k2-tree
A region quadtree for binary matrices originally designed to compress web graphs and as all compact data structures, allows accessing and querying the data without decompressing it.
General algorithm
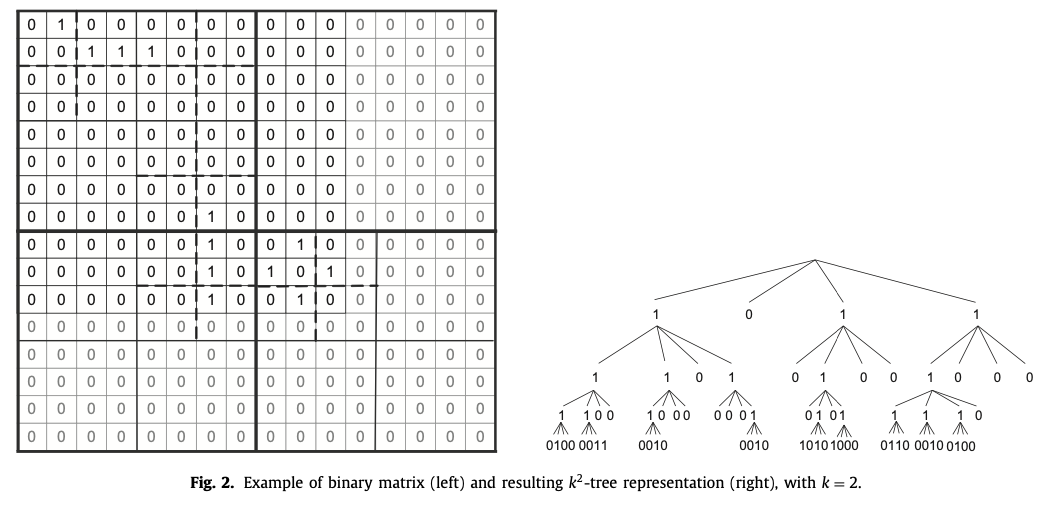
From a binary matrix of size \(n \times n\) and being \(k\) an input parameter, the k2-tree is built as a non-balanced k2-ary tree, where each node corresponds to a submatrix resulting from a recursive division of the matrix into \(k^2\) submatrices of teh same size.
- the first partition divides the original matrix into \(k\) rows and \(k\) columns of submatrices of size \(n^2/k^2\).
- Each of those submatrices generates a child node of the root having only one bit, whose value is 1 if there is at least one 1 in the cells of that submatrix.
- A 0 child means that the submatrix has all 0s and then the tree decomposition ends there.
This process continues until reaching a submatrix full of 0s or until reaching the cells of the original matrix (i.e. submatrices of size 1x1).
Representation & structure
Instead of using a pointer based representation, te tree is compactlyu represented by just using two bit maps \(T\) and \(L\), whose values are the bit values resulting from a breadth first traversal of the tree.
\(T\) stores all bits of the $k^2$-tree except those at the last level of the tree, whereas \(L\) stores the last level of the tree, thus containing the binary value of some original cells of the adjacency matrix. It is possible to navigate this space efficient representation by just accessing bitmapts \(T\) and \(L\).
We represent the whole adjacency matrix via the k2-tree using two bit arrays:
- T (tree): stores all the bits of the k2-tree except those in the last level. The bits are placed following a levelwise traversal: first the k2 binary values of the children of the root node, then the values of the second level, and so on.
- L (leaves): stores the last level of the tree. Thus it represents the value of (some) original cells of the adjacency matrix.
We create over T an auxiliary structure that enables us to compute rank queries efficiently. Given an offset i inside a sequence T of bits, rank(T, i) counts the number of times the bit 1 appears in T[1,i]. This can be supported in con- stant time and fast in practice using sublinear space on top of the bit sequence. In practice we use an implementation that uses 5% of extra space on top of the bit sequence and provides fast queries, as well as another that uses 37.5% extra space and is much faster.
Navigation
In particular it is possible to retrieve any cell, row, column, or region of the matrix in a very efficient time. This navigation is obtained by means of top down traversals in the conceptual tree, which are simulated with rank operations over \(T\).
Performance
Has excellent performance in both space and time when the binary matrix is sparse, with large zones of 0s and where the 1s are clustered. There also exists a variation of the k2-tree that compresses areas full of 1s.
Compressed 1 cluster variation
In this variation, subdivision ends when the algorithm finds a submatrix full of 0s or full of 1s, adding a method to distinguish black and white areas (1 and 0). Therefore the subdivision only continues when the submatrix has a mixture of 0s and 1s (gray zones). This representation is more suitable for representing other types of datasets different from web graphs, such as binary trees.
References
[1] Brisaboa, Nieves R. and Ladra, Susana and Navarro, Gonzalo, k2-Trees for Compact Web Graph Representation, Springer Berlin Heidelberg, 2009.
[2] Susana Ladra and Jos{\’{e}} R. Param{\’{a}} and Fernando Silva-Coira, Scalable and queryable compressed storage structure for raster data, Elsevier {BV}, 2017.